Harnessing AI in R and Python - Gather data with ChatGPT
What you will learn
- Learn the capabilities of ChatGPT in retrieving and structuring historical data from Wikipedia for analysis;
- Be comfortable with transforming text data into organized R and Pandas dataframes;
- Be able to write clear and specific prompts to achieve accurate and relevant responses from ChatGPT.
Table of Contents
AI in R and Python
Greetings, humanists, social and data scientists!
Welcome to this enlightening journey to extract historical data from the Web using AI! In this lesson, we delve into the innovative ways of harnessing the power of ChatGPT to gather data for your analyses. Specifically, you’ll learn how to command ChatGPT to retrieve historical data from a Wikipedia article and present it in a neat R and Pandas dataframe.
ChatGPT is an advanced large language model that has the remarkable capability to generate human-like text based on the prompts it receives. With ChatGPT, you can ask questions or provide instructions, and it will respond with relevant and coherent written answers. By the end of this post, the vast historical archives of Wikipedia will be just a prompt away, all thanks to the capabilities of ChatGPT.
Data source
The data used in this tutorial is presented in the Wikipedia article German casualties in World War II. This article offers an overview of the casualties sustained by the German Army during the Second World War.
1. Use ChatGPT to retrieve data in a Wikipedia table
The first step to gather the data is to access German casualties in World War II. This article provides an exploration of the number of deaths, wounded, and sick people during World War II in Germany.
Suppose you are interested in studying how the war differed across the different fronts and geographical regions. You see the second table presented in the article and would like to make a visualization showing the number of deaths in the German Army across the different war fronts. For small tables like this, you can simply select and copy the data you would like to transform in a dataframe, as shown in the figure below.
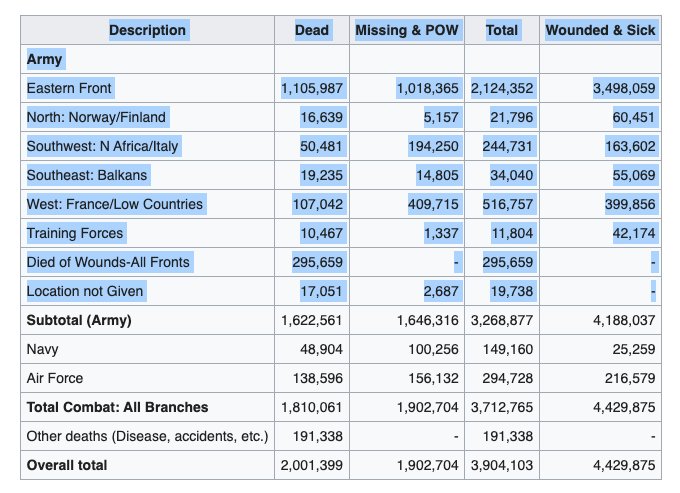
In this example, we will only gather the Army section of the table. Once you have copied the data, you are ready to use ChatGPT.
2. A good ChatGPT prompt
When writing prompts for ChatGPT, clarity and specificity are key. Start by providing enough context so the model understands what you’re asking. Being explicit about the format or type of answer you want can also help guide ChatGPT in generating a response that meets your expectations.
Additionally, including examples of desired responses can be beneficial. Always consider the “garbage in, garbage out” principle; a well-crafted prompt is more likely to result in a useful and coherent response.

For the R prompt, consult step 3 below and for the Python prompt jump to step 4.
3. AI for R
Below you can see a suggestion of prompt to ask ChatGPT to transform the text input copied from Wikipedia in an R dataframe. In the figure, we highlight each part of the prompt. Moreover, ChatGPT response is provided.

If you would like, you can copy the prompt here:
content_copy Copy
You are a data scientist investigating the number of deaths in the German Army during the Second World War. Please, could you transform the table below into an R data frame made with the data.frame( ) function? The character "-" should be replaced by NA. The table was copied from a Wikipedia place and is as follows: """
Description Dead Missing & POW Total Wounded & Sick
Army
Eastern Front 1,105,987 1,018,365 2,124,352 3,498,059
North: Norway/Finland 16,639 5,157 21,796 60,451
Southwest: N Africa/Italy 50,481 194,250 244,731 163,602
Southeast: Balkans 19,235 14,805 34,040 55,069
West: France/Low Countries 107,042 409,715 516,757 399,856
Training Forces 10,467 1,337 11,804 42,174
Died of Wounds-All Fronts 295,659 - 295,659 -
Location not Given 17,051 2,687 19,738 - """And here is the model’s answer:
content_copy Copy
df <- data.frame(
Description = c("Eastern Front", "North: Norway/Finland", "Southwest: N Africa/Italy", "Southeast: Balkans", "West: France/Low Countries", "Training Forces", "Died of Wounds-All Fronts", "Location not Given"),
Dead = as.integer(gsub(",", "", c("1105987", "16639", "50481", "19235", "107042", "10467", "295659", "17051"))),
Missing_POW = as.integer(gsub(",", "", c("1018365", "5157", "194250", "14805", "409715", "1337", NA, "2687"))),
Total = as.integer(gsub(",", "", c("2124352", "21796", "244731", "34040", "516757", "11804", "295659", "19738"))),
Wounded_Sick = as.integer(gsub(",", "", c("3498059", "60451", "163602", "55069", "399856", "42174", NA, NA)))
)And that’s it. In a few seconds you have your data formatted in a nice dataframe, ready to be analyzed.
Now we will make a simple bar plot to visualize the total number of deaths by front. To do that, we use ggplot. Note that we reorder the variable Description so that it is ordered from the largest number of deaths to the smallest. Moreover, we also divide Total by one million to have millions of deaths in the x axis. To add a customized ggplot2 theme, like the one in the plot presented below, check the lesson ‘Climate data visualization with ggplot2’
content_copy Copy
ggplot(df, aes(y = reorder(Description, Total), x = Total/1000000)) +
geom_bar(stat = "identity", fill = "#FF6885")+
labs(title = "Deaths in the German Army by location or cause",
subtitle = "Second World War (1939-1945)",
y = "Front/Cause",
x = "Number of Deaths [in millions]",
caption = "Source: German casualties in World War II. Wikipedia")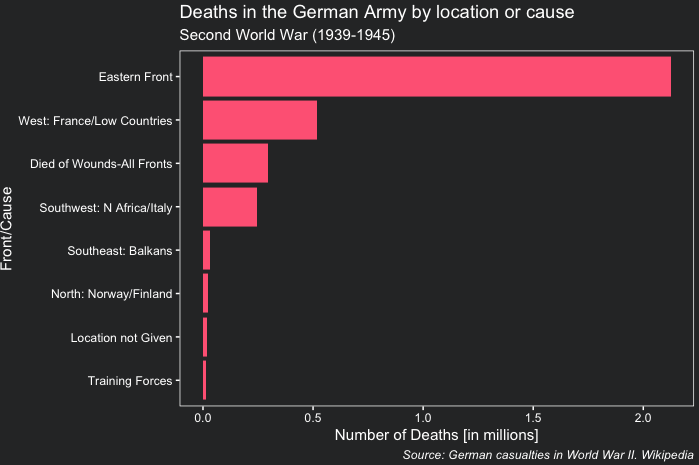
It is remarkable that most of casualties occurred in the Eastern Front while the least lethal front was in the nordic countries.
4. AI for Python
The prompt for achieving the same result in Python is almost the same, but we ask for a Pandas data frame, instead of an R data frame.
content_copy Copy
You are a data scientist investigating the number of deaths in the German Army during the Second World War. Please, could you transform the table below into a Pandas data frame? The character "-" should be replaced by NA. The table was copied from a Wikipedia place and is as follows: """
Description Dead Missing & POW Total Wounded & Sick
Army
Eastern Front 1,105,987 1,018,365 2,124,352 3,498,059
North: Norway/Finland 16,639 5,157 21,796 60,451
Southwest: N Africa/Italy 50,481 194,250 244,731 163,602
Southeast: Balkans 19,235 14,805 34,040 55,069
West: France/Low Countries 107,042 409,715 516,757 399,856
Training Forces 10,467 1,337 11,804 42,174
Died of Wounds-All Fronts 295,659 - 295,659 -
Location not Given 17,051 2,687 19,738 - """This prompts correctly organizes the data in a Pandas data frame, as shown below:
content_copy Copy
import pandas as pd
import numpy as np
data = {
"Description": ["Eastern Front", "North: Norway/Finland", "Southwest: N Africa/Italy", "Southeast: Balkans", "West: France/Low Countries", "Training Forces", "Died of Wounds-All Fronts", "Location not Given"],
"Dead": [1105987, 16639, 50481, 19235, 107042, 10467, 295659, 17051],
"Missing & POW": [1018365, 5157, 194250, 14805, 409715, 1337, np.nan, 2687],
"Total": [2124352, 21796, 244731, 34040, 516757, 11804, 295659, 19738],
"Wounded & Sick": [3498059, 60451, 163602, 55069, 399856, 42174, np.nan, np.nan]
}
df = pd.DataFrame(data)
print(df)Keep in mind that accuracy is not one of ChatGPT’s strengths. While I have not seen any mistakes in the code above, it is always good to revise ChatGPT’s work. Let me know if you have any suggestions on how to improve this method. Also, leave any questions or concerns you might have in the comments below.
Conclusions
- ChatGPT is a powerful tool that can be utilized to efficiently gather and organize historical data from the web, specifically Wikipedia, into structured data frames for analysis in R and Python;
- Clarity and specificity are essential when crafting prompts for ChatGPT to ensure accurate and relevant responses;
- While this method is highly effective for small tables, it’s important to note that ChatGPT may suggest alternative solutions such as web scraping for larger and more complex tables, and to always review ChatGPT’s output for accuracy.
Comments
There are currently no comments on this article, be the first to add one below
Add a Comment
If you are looking for a response to your comment, either leave your email address or check back on this page periodically.