Explore art with SQL and pd.read_sql_query
What you will learn
- Be able to create a SQL database from csv files;
- Use the psycopg2 library to connect Python and your SQL database;
- Be comfortable using pd.read_sql_query to extract data into a Pandas dataframe.
Table of Contents
- 1. Data source
- 2. Download and install PostgreSQL and pgAdmin
- 3. Creating the database and its tables
- 4. Exploring the data with SQL commands
- 5. Using pd.read_sql_query to access data
- 6. Visualizing the most popular styles
- 6. Conclusions
Greetings, humanists, social and data scientists!
Have you ever tried to load a large file in Python or R? Sometimes, when we have file sizes in the order of gigabytes, you may experience problems of performance with your program taking an unusually long time to load the data. SQL, or Structured Query Language, is used to deal with larger data files stored in relational databases and is widely used in the industry and even in research. Apart from being more efficient to prepare data, in your journey, you might encounter data sources whose main form of access is through SQL.
In this lesson you will learn how to use SQL in Python to retrieve data from a relational data base of the National Gallery of Art (US). You will also learn how to use a relational database management system (RDBMS) and pd.read_sql_query to extract data from it in Python.
1. Data source
The database used in this lesson is made available by National Gallery of Art (US) under a Creative Commons Zero license. The dataset contains data about more than 130,000 artworks and their artists since the Middle Ages until the present day.
It is a wonderful resource to study history and art. Variables available include the title of the artwork, dimensions, author, description, location, country where it was produced, the year the artist started the work and the year he or she finished it. These variables are only some examples, but there is much more to explore.
2. Download and install PostgreSQL and pgAdmin
PostgreSQL is a free and very popular relational database management system. It stores and manages the tables contained in a database. Please, consult this guide to install it in your computer.
After you install PostgreSQL, you will need to connect to the Postgre database server. In this tutorial, we will be using the pgAdmin application to establish this connection. It is a visual and intuitive interface and makes many operations easier to execute. The guide above will also guide you through the process of connecting to your local database. In the next steps, after being connected to your local database server, we will learn how to create a database that will store the National Gallery Dataset.
3. Creating the database and its tables
After you are connected to the server, click “Databases” with the right mouse button and choose “Create” and “Database…” as shown in the image below.
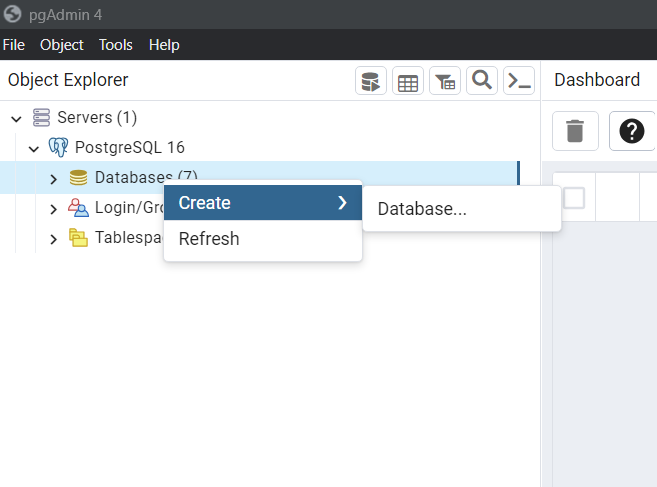
Next, give a title to your database as shown in the figure below. In our case, it will be called “art_db”. Click “Save” and it is all set!
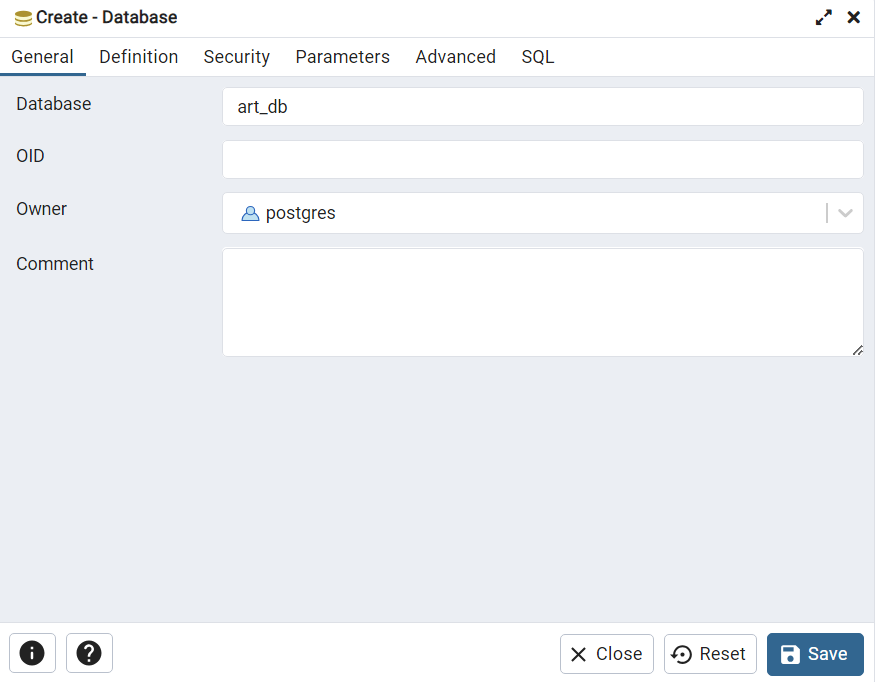
With the database ‘art_bd’ selected, click the ‘Query Tool’ as shown below.
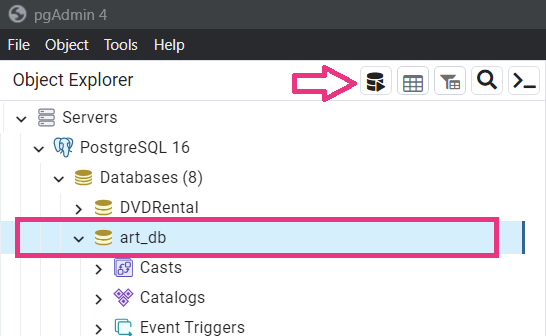
This will open a field where you can type SQL code. Our objective is to create the first table of our database, which will contain the content of ‘objects.csv’ available in the GitHub account of the National Gallery of Art, provided in the Data section above.
To create a table, we must specify the name and the variable type for each variable in the table. The SQL command to create a table is quite intuitive: CREATE TABLE name_of_your_table. Copy the code below and paste it in the window opened by the ‘Query Tool’. The code specify each variable of the objects table. This table contains information on each artwork available in the collection.
content_copy Copy
CREATE TABLE objects (
objectID integer NOT NULL,
accessioned CHARACTER VARYING(32),
accessionnum CHARACTER VARYING(32),
locationid CHARACTER VARYING(32),
title CHARACTER VARYING(2048),
displaydate CHARACTER VARYING(256),
beginyear integer,
endyear integer,
visualbrowsertimespan CHARACTER VARYING(32),
medium CHARACTER VARYING(2048),
dimensions CHARACTER VARYING(2048),
inscription CHARACTER VARYING,
markings CHARACTER VARYING,
attributioninverted CHARACTER VARYING(1024),
attribution CHARACTER VARYING(1024),
provenancetext CHARACTER VARYING,
creditline CHARACTER VARYING(2048),
classification CHARACTER VARYING(64),
subclassification CHARACTER VARYING(64),
visualbrowserclassification CHARACTER VARYING(32),
parentid CHARACTER VARYING(32),
isvirtual CHARACTER VARYING(32),
departmentabbr CHARACTER VARYING(32),
portfolio CHARACTER VARYING(2048),
series CHARACTER VARYING(850),
volume CHARACTER VARYING(850),
watermarks CHARACTER VARYING(512),
lastdetectedmodification CHARACTER VARYING(64),
wikidataid CHARACTER VARYING(64),
customprinturl CHARACTER VARYING(512)
);The last step is to load the data from the csv file into this table. This can be done through the ‘COPY’ command as shown below.
content_copy Copy
COPY objects (objectid, accessioned, accessionnum, locationid, title, displaydate, beginyear, endyear, visualbrowsertimespan, medium, dimensions, inscription, markings, attributioninverted, attribution, provenancetext, creditline, classification, subclassification, visualbrowserclassification, parentid, isvirtual, departmentabbr, portfolio, series, volume, watermarks, lastdetectedmodification, wikidataid, customprinturl)
FROM 'C:/temp/objects.csv'
DELIMITER ','
CSV HEADER;Great! Now you should have your first table loaded to your database. The complete database includes more than 15 tables. However, we will only use two of them for this example, as shown in the scheme below. Note that the two tables relate to each other through the key variable objectid.
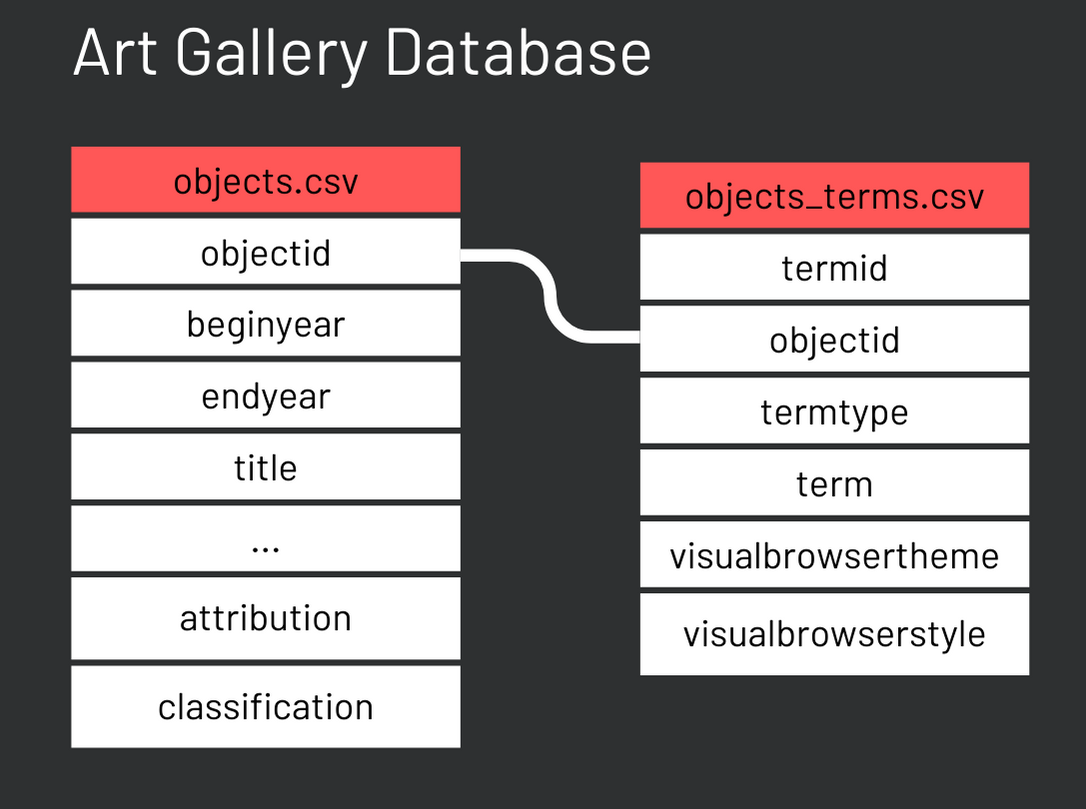
To load the “objects_terms” table, please repeat the same procedure with the code below.
content_copy Copy
CREATE TABLE objects_terms (
termid INTEGER,
objectid INTEGER,
termtype VARCHAR(64),
term VARCHAR(256),
visualbrowsertheme VARCHAR(32),
visualbrowserstyle VARCHAR(64)
);
COPY objects_terms (termid, objectid, termtype, term, visualbrowsertheme, visualbrowserstyle)
FROM 'C:/temp/objects_terms.csv'
DELIMITER ','
CSV HEADER;4. Exploring the data with SQL commands
Click the ‘Query Tool’ to start exploring the data. First, select which variables you would like to include in your analysis. Second, you tell SQL in which table this variables are. The code below selects the variables title and attribution from the objects table. It also limits the result to 5 observations.
content_copy Copy
SELECT title, attribution
FROM objects
LIMIT 5Now, we would like to know what are the different kinds of classification in this dataset. To achieve that, we have to select the classification variable, but including only distinct values.
content_copy Copy
SELECT DISTINCT(classification)
FROM objectsThe result tells us that there are 11 classifications: “Decorative Art”, “Drawing”, “Index of American Design”, “Painting”, “Photograph”, “Portfolio”, “Print”, “Sculpture”, “Technical Material”, “Time-Based Media Art” and “Volume”.
Finally, let us group the artworks by classification and count the number of objects in each category. COUNT(*) will count the total of items in the groups defined by GROUP BY. When you select a variable you can give it a new name with AS. Finally, the command ORDER BY orders the classification by number of items in a descending order (DESC).
content_copy Copy
SELECT classification, COUNT(*) as n_items
FROM objects
GROUP BY classification
ORDER BY n_items DESCNote that prints is the largest classification, followed by photographs.
5. Using pd.read_sql_query to access data
Now that you have your SQL database working, it is time to access it with Python. Before using Pandas, we have to connect Python to our SQL database. We will do that with psycopg2, a very popular PostgreSQL adapter for Python. Please, install it with pip install psycopg2.
We use the connect method of psycopg2 to establish the connection. It takes 4 main arguments:
- host: in our case, the database is hosted locally, so we will pass localhost to this parameter. Note, however, that we could specify an IP if the server was external;
- database: the name given to your SQL database, art_db;
- user: user name required to authenticate;
- password: your database password.
content_copy Copy
import psycopg2
import pandas as pd
conn = psycopg2.connect(
host="localhost",
database="art_db",
user="postgres",
password="*******")The next step is to store our SQL query in a string Python variable. The query below performs a LEFT JOIN with the two tables in our database. The operation uses the variable objectid to join the two tables. In practice we are selecting the titles, authors (attribution), classification - we keep only “Painting” with a WHERE command -, and term - we filter only terms that specify the “Style” of the painting.
content_copy Copy
command = ''' SELECT o.title, o.attribution, o.classification, ot.term
FROM objects as o
LEFT JOIN objects_terms as ot ON o.objectid = ot.objectid
WHERE classification = 'Painting' AND termtype = 'Style' '''Finally, we can extract the data. Use the cursor() method of conn to be able to “type” your SQL query. Pass the command variable and connection object to
pd.read_sql_query and it will return a Pandas dataframe with the data we selected. Next, commit and close cursor and connections.
content_copy Copy
# open cursor to insert our query
cur = conn.cursor()
# use pd.read_sql_query to query our database and get the result in a pandas dataframe
paintings = pd.read_sql_query(command, conn)
# save any changes to the database
conn.commit()
# close cursor and connection
cur.close()
conn.close()6. Visualizing the most popular styles
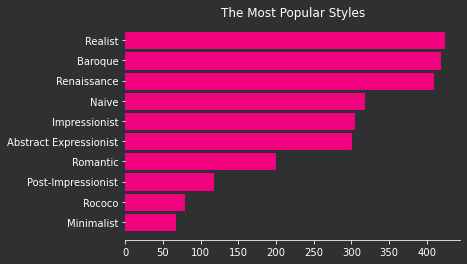
From the data we gathered from our database, we would like to check which are the 10 most popular art styles in our data, by number of paintings. We can use the value_counts() method of the column term to count how many paintings are classified in each style.
The result is a Pandas Series where the index contains the styles and the values contain the quantities of paintings of the respective style. The remaining code produces an horizontal bar plot showing the top 10 styles by number of paintings. If you would like to learn more about data visualization with matplotlib, please consult the lesson Storytelling with Matplotlib - Visualizing historical data.
content_copy Copy
import matplotlib.pyplot as plt
top_10_styles = paintings['term'].value_counts().head(10)
fig, ax = plt.subplots()
ax.barh(top_10_styles.index, top_10_styles.values,
color = "#f0027f",
edgecolor = "#f0027f")
ax.set_title("The Most Popular Styles")
# inverts y axis
ax.invert_yaxis()
# eliminates grids
ax.grid(False)
# set ticks' colors to white
ax.tick_params(axis='x', colors='white')
ax.tick_params(axis='y', colors='white')
# set font colors
ax.set_facecolor('#2E3031')
ax.title.set_color('white')
# eliminates top, left and right borders and sets the bottom border color to white
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
ax.spines["bottom"].set_color("white")
# fig background color:
fig.patch.set_facecolor('#2E3031')Note that Realist, Baroque and Renaissance are the most popular art styles in our dataset.
Please feel free to share your thoughts and questions below!
6. Conclusions
- It is possible to create a SQL database from csv files and access it with Python;
- psycopg2 enables connection between Python and your SQL database;
- pd.read_sql_query can be used to extract data into a Pandas dataframe.
Comments
There are currently no comments on this article, be the first to add one below
Add a Comment
If you are looking for a response to your comment, either leave your email address or check back on this page periodically.