Master geom_smooth, cor.test, and stargazer in R - A Guide to Analyzing Data Relationships
What you will learn
- Become comfortable with geom_smooth to analyse relationships;
- Gain confidence in interpreting cor.test in R;
- Learn how to show regression results in R using stargazer.
Table of Contents
- 1. How to use geom_smooth to evaluate relationships in R?
- 2. cort.test in R
- 3. How to interpret cort.test in R?
- 4. How to use stargazer in R?
- Conclusions
1. How to use geom_smooth to evaluate relationships in R?
The geom_smooth layer in ggplot2 allows you to depict a regression line in just a few steps. To exemplify its use, we will use the Guerry dataset, provided by the R package HistData. It includes data on several social variables of 86 French departments in the 1830s. To learn more about this package, please refer to our lesson ‘Uncovering History with R - A Look at the HistData Package’.
First, we need to load the HistData package. After doing so, we can use the command help(Guerry) to view the dataset’s description about each of the 23 variables. Variables include information such as population, crime, literacy, suicide, wealth, and location.
You can use df <- Guerry to load the data. Feel free to explore the dataset and check the structure of the dataframe with str(df).
content_copy Copy
library(HistData)
library(ggplot2)
help(Guerry)
df <- Guerry
str(df)In the documentation of the dataset, the author states “Note that most of the variables (e.g., Crime_pers) are scaled so that ‘more is better’ morally.”. Thus, suicide, for example, is expressed as the population divided by the number of suicides. In this way, the fewer the suicides, the larger the value in the Suicides column.
To make our analysis easier to interpret, we can calculate the inverse of Suicides, that is, instead of having population/suicides, we will consider suicides/population (suicides per inhabitant). Moreover, to avoid very small numbers, let us multiply this by 100,000 so that we have suicides per 100,000 population. The code below creates this new variable.
content_copy Copy
df$Suicides_Pop <- (1/df$Suicides)*100000To depict the relationship between suicides and literacy, an easy and quick method is to plot the regression line between these variables. To know more about linear regression, check out the lesson R programming for climate data analysis and visualization. In the code below, we use geom_smooth with the method argument set to “lm”. This tells ggplot to use a linear model (lm) to depict the relationship. geom_point adds a scatterplot to enrich the analysis. Please note that the code below incorporates the function theme_coding_the_past to style the plot. You can access this theme in the lesson ‘Climate Data Visualization’
content_copy Copy
ggplot(data = df, aes(x = Literacy, y = Suicides_Pop))+
geom_point(color = "#FF6885", size = 2)+
geom_smooth(method = "lm", color = "white", se = FALSE)+
labs(title = "Relationship between Suicides and Literacy",
x = "Percentage of literate conscripts",
y = "Suicides (per 100,000 population)")+
theme_coding_the_past()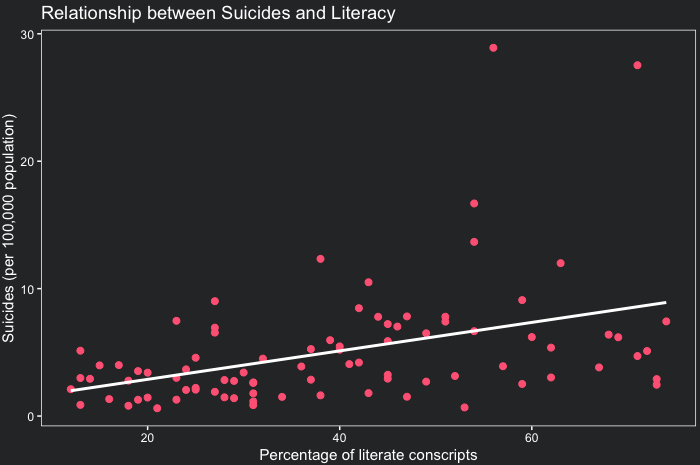
2. cort.test in R
Having observed a graphical association between Literacy and Suicides, let’s use cor.test to find this association analytically. This function takes two arguments x and y and returns a Pearson correlation coefficient (by default) and its statistical significance. As explained in the lesson R programming for climate data analysis and visualization “correlation measures how much two variables change together. It ranges from 1 to -1, where 1 means perfect positive correlation, 0 means no correlation at all and -1 means perfect negative correlation”. Use the code below to calculate the correlation between suicides and literacy rates.
content_copy Copy
cor.test(x = df$Literacy, df$Suicides_Pop)3. How to interpret cort.test in R?
After running the code above, we obtain a correlation coefficient of 0.4, which indicates a moderate positive correlation. As literacy increases so does suicide proportion. The cor.test function also provides a p-value, that in this case is less than 0.01, meaning there is a statistically significant association between Literacy and Suicides_Pop. Framed differently, under the hypothesis that there is no correlation between the two variables, the probability of finding a coefficient of 0.4 or higher would be less than 1%. So we can reject the null hypothesis that assumes no relationship between the two variables.
Note that we cannot say that higher literacy rates directly cause more suicides, as factors beyond literacy rates might influence suicide rates. In the next section, we will check whether wealth and the distance to Paris influence suicides as well. Moreover, we will determine if the association between literacy and suicides holds even after controlling for these variables. To show the results, we will use stargazer, a very handy package designed for displaying linear model results.
4. How to use stargazer in R?
The stargazer package offers a neat and practical way of presenting the results of several linear models. Users can set it up to produce LaTeX or HTML outputs using the type argument. In the code that follows, we configure it to generate HTML, making it suitable for this blog post. First, we create three models adding variables indicating the wealth and distance to Paris of each department. Second, we pass these models to stargazer.
content_copy Copy
linear_model_01 <- lm(Suicides_Pop ~ Literacy, data = df)
linear_model_02 <- lm(Suicides_Pop ~ Literacy + Wealth, data = df)
linear_model_03 <- lm(Suicides_Pop ~ Literacy + Wealth + Distance, data = df)
library(stargazer)
stargazer(linear_model_01, linear_model_02, linear_model_03, type = "html")The stargazer table can be seen below. The first model only includes Suicides_Pop as the dependent variable and Literacy as the independent variable. The literacy coefficient tells us that if we increase the literacy rate by 1%, then the suicide proportion grows by 0.11. Put differently, a 10% increase in literacy is associated with around 1 suicide more per 100,000 population. This estimate is statistically significant.
Note in model 2 that Wealth appears to influence Suicides negatively, meaning that richer areas are associated with fewer suicides. The coefficient regarding Literacy decreases a bit but remains statistically significant. Finally, model 3 includes the distance to Paris as an additional variable. The coefficient of Literacy decreases again but remains statistically significant. Moreover, being close to Paris is associated with more suicides.
| Dependent variable: | |||
| Suicides_Pop | |||
| (1) | (2) | (3) | |
| Literacy | 0.112*** | 0.080*** | 0.064** |
| (0.027) | (0.026) | (0.025) | |
| Wealth | -0.080*** | -0.059*** | |
| (0.018) | (0.018) | ||
| Distance | -0.014*** | ||
| (0.004) | |||
| Constant | 0.645 | 5.347*** | 7.901*** |
| (1.168) | (1.489) | (1.604) | |
| Observations | 86 | 86 | 86 |
| R2 | 0.167 | 0.329 | 0.408 |
| Adjusted R2 | 0.157 | 0.313 | 0.386 |
| Residual Std. Error | 4.360 (df = 84) | 3.938 (df = 83) | 3.720 (df = 82) |
| F Statistic | 16.826*** (df = 1; 84) | 20.321*** (df = 2; 83) | 18.841*** (df = 3; 82) |
| Note: | *p<0.1; **p<0.05; ***p<0.01 | ||
Like all social phenomena, the incidence of suicide is shaped by a multitude of factors. While we cannot definitively claim that literacy directly caused suicides in 19th-century France, our analysis above does indicate an association between these variables. Delving deeper into the contextual nuances of France in the 1830s might shed light on whether literacy indeed influenced the decision to commit suicide. For instance, check this article by Lisa Lieberman “Romanticism and the Culture of Suicide in Nineteenth-Century France”
If you are interested in this topic, The Sorrows of Young Werther, by Johann Wolfgang Goethe, is a literary representation of a particular view on suicide that would influence the Romantic movement in 19th-century Europe.
 Daniel Chodowiecki. Goethe’s Werther in his bedroom, with him lying dead on his bed. Public Domain.
Daniel Chodowiecki. Goethe’s Werther in his bedroom, with him lying dead on his bed. Public Domain.
If you have any questions or would like to share your thoughts on this topic, please feel free to ask in the comments below.
Conclusions
- geom_smooth offers an easy way to depict a linear regression
- To calculate the correlation of two variables along with its statistical significance, use cor.test;
- Finally, stargazer offers a clean and effective way of summarizing several linear models in R
Comments
There are currently no comments on this article, be the first to add one below
Add a Comment
If you are looking for a response to your comment, either leave your email address or check back on this page periodically.